
#begin
This is the fifth and last blog in the series about the SOLID principles of Object Oriented Design. It is all about the D in SOLID, the Dependency Inversion Principle. If you missed the first four blogs in this series, you can read them here: S, O, L and I.
The Dependency Inversion Principle (DIP) has been this one principle that really took some time to sink in properly. I think we all learn in school, or where ever else, that you must always try to program with abstract concepts because it makes your code more flexible. I think some of my earlier blogs about SOLID have explained this nicely. What they often do not explain in school is the true purpose of DIP, which is; switching source code dependencies into run-time dependencies.
I think the DIP is at the root of good, clean software design and architecture. My opinion is that without the DIP, you cannot write quality OOP code. Without it, the system will become unmanageable and incomprehensible very fast due to dependencies everywhere.
In this blog, I’m going to try my best to explain what DIP is and why it is such an important principle. It took quite a while for me to truly understand this principle but once it clicked, it really changed the way I looked at, and used, interfaces specifically.
The Dependency Inversion Principle
So what exactly does the DIP say? Well, there is no clear description about this principle. The descriptions vary a bit depending on what source you have. Uncle Bob’s Clean architecture book says the following:
The Dependency Inversion Principle (DIP) tells us that the most flexible systems are those in which source code dependencies refer only to abstractions, not concretions. [1]
Now, this is still kind of vague and seems more like a statement than a description or explanation. In another book by Uncle Bob: Agile Software Development: Principles, Patterns, and Practices [2], the principle is stated somewhat clearer.
- High-level modules should not depend on low-level modules. Both should depend on abstractions (e.g., interfaces).
- Abstractions should not depend on details. Details (concrete implementations) should depend on abstractions.
There are multiple reasons to do this. One of them is that, in general, abstractions are more stable than concrete implementations. You do not often change the signature of an interface for example, but you will change it’s implementation here and then, when requirements change or you gained some new insights. So concrete implementations are more volatile than abstractions.
Also, by depending on abstract things, interfaces specifically (in statically typed OOP languages) you can switch source code dependencies into run-time dependencies, which is the core idea of OOP.
But what exactly does the summary above mean? Well, in regards to point A; I can explain it through a simple mistake I made myself, and you probably did too. When we needed to write software in school we often needed/chose to use some variant of a layered architecture. Because it was convenient or simply exactly what we needed to get the job done. Let’s face it; the software you needed to write in school was never that complex that it needed some exotic architecture, so a 3 or 5 layered architecture was often more than enough. In a particular project meed needed too write some software for a fictional travel company; we needed to write a program that would allow the user to plan bus rides between locations as efficient as possible. So there was some UI, business layer and data access layer involved. I chose to write this using a 3 layered architecture.
When I had it all done, and went to a teacher for some feedback he told me that it looks nice, functions well, but the dependencies are incorrect. He said that the outer layers’ dependencies must be switched around. At first I did not really understand what he meant but after he drew some UML on a piece of paper it became clear to me.
In my current design; the UI knew about my business logic, the DAL knew about the business logic, and the business logic knew about both the UI and the DAL. So it was a dependency nightmare, but manageable because it was a small project, and made by 1 person; me.
So I created some interfaces and stuck them at the edges of my business layer and made the DAL and the UI implement them. This way, my business logic was no longer depending on the outer layers and I had essentially created a very minimal implementation of an hexagonal architecture.
Point B, to me, sounds like a restatement of point A, but then on the level of classes instead of components of layers. What it means is that you never depend on concrete classes but on abstractions instead.
The Four Dependency Rules
In Uncle Bob’s book, Clean Architecture, Robert defines 4 coding practices for compliance to the DIP.
Don’t refer to volatile concrete classes.
Always try to refer to abstract interfaces instead. He says this is independent of language you use, static or dynamically typed. Reffering to abstractions only encourages or enforces the use of abstract factories
Don’t derive from volatile concrete classes.
This is essentially the same as the previous rule but with a special focus on inheritance. Inheritance is the strongest dependency you can create in statically typed OOP languages. You should use it with great care, and use it with caution.
Don’t override concrete functions.
Concrete functions often require concrete source code dependencies, so when you override them, you are required to reference concrete concepts, and thereby inherit the dependencies. In order to fix this, you should create an abstract base function, and create different implementations.
Never mention the name of anything concrete and volatile.
This is just a restatement of the principle itself. I’m not sure why Uncle Bob would add this, maybe he just wanted to have an even number of practices.
Impact on Software Architecture
Now we are getting to the more interesting part of the blog; the impact of the DIP on software architecture. As I said before, I think the DIP is the driving force behind good, clean quality software. When it comes to explaining the DIP in regard to architecture I will first take a step down back to the class level and explain it through the design pattern: Abstract Factory Pattern because it is the perfect example of how to use the DIP.
Uncle Bob always uses the same example for explaining the principle so I will do so too.
Dependencies to concrete objects often occur during their creation because that is when you need to instantiate and configure them correctly. In OOP languages we would often use the Abstract Factory Pattern (AFP) to manage these undesirable dependencies.
The diagram below shows a basic implementation of the AFP.
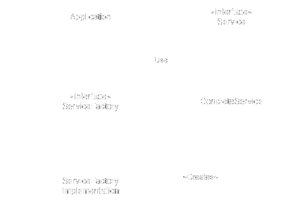
Here we have a scenario where the Application class needs to create some service(s). We use the AFP to control the dependencies the Application has to the actual concrete services. This is why we created an interface for a ServiceFactory and Service, which are in the same component as the Application class. The curved line in the diagram is an architectural boundary.
Below the boundary we can see a FactoryServiceImplementation and ConcreteService that implement the ServiceFactory and Service interface respectively.
So in this example we can see that the abstract component contains only high-level business rules, and the concrete component contains all the details of how these business rules interact. An important thing to note here is that, ALL the arrows cross the curved line in the same direction. This is very, very important. Because this is the DIP doing it’s work.
When we implement the code like in the diagram we can switch the flow of control; We can turn source code dependencies into run-time dependencies. Imagine the following scenario; for testing purposes we have a special “ConcreteTestService” which is just a Mock for the ConcreteService class. We can control this service during testing and make sure the software behaves correct.
Because we implemented the code following the AFP we can swap the concrete component with our testing component very easily because the abstract component has no knowledge of it. The abstract component remains unchanged when we want to swap out the concrete component.
Let me restate that; we do NOT have to recompile our software when we want to swap out the concrete component!
This is some very powerful behaviour! It will save you lots of headaches and time because the testing component wont be the only component that we will be able to swap out. What components would we want to swap out? Well probably we would want to be able to swap out our UI component because there is a new JS framework every single day and the sales or marketing teams makes absurd decisions to change the UI. Or we might want to add some CLI to the software without recompiling all other components. Another nice effect we get from this is when we would like to swap out database engines. I think everyone, working in some legacy system would really like to swap out their SQL database… but they can’t because they use an ORM and now have mapping annotations spread across their business entities. Yeah, I’ve been there too! When we would have isolated all Database and ORM logic in a single component and made it a plugin to the abstract core, we would have been able to swap out databases easily. It would probably still be a lot of work to actually do it, but we could do it! The option would be there and we would not be stuck with some prehistory SQL database we all hate.
If you know about Clean, Hexagonal, union, vertical slice, or plugin architecture (and probably more) this might all sound very familiar. And that is true, because in these architectures, the DIP is taken as one of the core design principles and an entire architecture is built around it.
The Component level
So let’s step up the level of abstraction from the class level again, and get back to the level of architecture. More specifically, the component level. Because on the component level there are three very interesting rules that help you tackle component coupling.
- The Acyclic Dependencies Principle (ADP)
- The Stable Dependencies Principle (SDP)
- The Stable Abstraction Principle (SAP)
Let’s discuss each of them separately.
The Acyclic Dependencies Principle
This ADP states the following:
Allow no cycles in the component dependency graph
To explain this, I will give a short example of what a violation of this principle will lead to. I think everyone, at multiple points in their software development career has run into the problem of integrating their pull/merge request into the stable branch of the software. I’m not talking about merge conflicts here but really just the integration of multiple features. We have all checked in, and merged code that worked perfectly fine, only to be confronted by it not working the next morning. So you are blamed for checking in crap and you start digging into it, and very soon you realize that it only got broken after another colleague merged code that seemed to be totally unrelated. And so the blaming war begins… since your colleague merged his code last, it was his responsibility to test it all again. (But were there unit-tests for your own part? How would your colleague know what to test?)
When both of you pair on this particular issue, you quickly find out both of your features depend on the same component somewhere deep in the dependency graph. Your colleague needed to change small bits in here, but you did not change anything here, that’s why there weren’t any merge conflicts and it did not get noticed.
I think this problem happens a lot, I experience it too, and it is really difficult to completely eliminate this, if not impossible. To me this all feels part of the job. Trying to manage all dependencies in a system, and, it’s quite challenging sometimes.
But… when we have the ADP we can use to try make sense of the component dependencies. What the ADP essentially says is that we may not have any cycles in our dependency graph, no direct nor indirect cycles!
So as in the diagram below (this is also an example taken from the Clean Architecture book, meybe you recognize the Clean Architecture flow of control and components), there are no cycles anywhere in the graph. You can follow the lines in the graph, but never end up in de same component twice. Also notice that the main component has the most dependencies of any component in the graph. The Main component is used to initialize the system and create the necessary factories and services to operate the system. Another important aspect of the Main component is, if it ever needs to recompile, not a single other component would care. None of them depend on Main, Main depends on them!
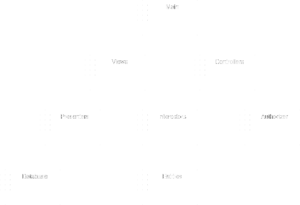
The strength of this principle comes from the fact that, when you release a component, you can easily check the graph and see which ones are dependent and should be considered for testing. Also, when multiple components are being developed at the same time, the developers can work together more effectively when they need to release.
This of course, is an ideal world; what would happen if there is a cycle anywhere in the graph? Well, in a directed graph it is easy to see which components need to be compatible with each other. Just the components it depends on, but witch one cycle, or more, this can become really difficult really fast. Think about how to test these components, if there are cycles, where do you start? And how would you properly generate DLL or Jar files for these components independently?
So, we need to break cycles as soon as possible, at any cost, to save of some headaches in the future. But how do we do this? You might have guessed it already, yeah with an interface of course. You apply the DIP at the edges of the component you are trying to isolate, and you will be able to break any cycle in the graph.
Any system that is actively being developed will grow in the number of components. Components do not need to be bound to some particular high level function, but they represent a map for buildability and maintainability. Many developers often think of components as pieces of their system that fulfill a specific function or role. But when you shift that believe towards the buildability and maintainablity aspect you will be able to create far more stable systems. This is the reason why your component diagrams are always wrong if you design them before you write any code. Because, if you want to manage your dependencies effectively, you will need to split things up at some point.
The Stable Dependencies Principle
Next up is the SDP, which says the following:
Depend in the direction of stability
This seems intuitive… It essentially says that volatile components are always isolated and stable components never depend on volatile components. I think everyone will agree this is a good idea. Certain components change a lot, like the UI for example, you would want to isolate any changes made to the UI from you business rules or database access.
But let’s dive deeper in the notion of “stability”. How would we define stability of a component and how do we measure it?
Webster’s Dictionary defines stability as “the strength to stand and endure”. Stability is related to the amount of work needed to make a change or manipulate something. So how does this relate to software?
Well there are many factors that make software hard to change, like sheer size, complexity of the component and readability of the code among things. But, for the SDP specifically we need to focus on dependencies. A component with lots of incoming dependencies is aught to be very stable because it requires a lot of reconcile to do any changes to it. Also having a component with just incoming dependencies yet no outgoing makes it independent which can also contribute to stability.
What makes components unstable is have many outgoing dependencies because if any of those change the component needs to be retested and maybe recompiled as well. So what metrics can we define to measure the stability of a component?
In Uncle Bob’s book, Clean architecture he defines three metrics to consider when trying to figure out the positional stability of a component. Positional here refers to the position a component has in a specific component diagram.
The metrics are:
- Fan-in: Incoming dependencies. This metric defines the number of classes outside this component that depend on classes within this component.
- Fan-out: Outgoing dependencies. This metric identifies the number of classes inside this component that depend on classes outside the component.
- I: Instability:= Fan-out / (Fan-in + Fan-out). This metric has the range [0, 1]. I = 0 means a maximally stable component. I = 1 means a maximally instable component.
In publications about coupling the fan-in and fan-out metrics are called Afferent and Efferent couplings respectively.
Let’s take a look at an example (slight variation of the example in Clean Architecture):
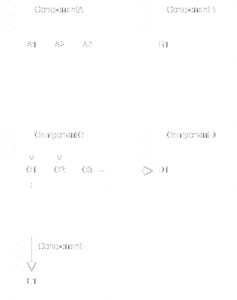
The diagram above shows 5 components. Let’s calculate the stability metric of ComponentC. We first need to sum the number of classes outside ComponentC that depend on classes inside ComponentC, which are 3. Then we need to sum the number of classes inside ComponentC that depend on classes outside ComponentC, which are 2. Thus we get a formula instability = 2 / (3+ 2) = 2 /5 = 1 /10.
But, now we have some value, what do we do with it? Well the rule is that a component may never depend on another component with a lesser Instability metric. You are only allowed to depend on components that have a greater instability metric than the component itself.
Then, the last thing I want to say about the SDP is that not all components in a system must be stable. Because if all components are stable, you have made an unchangeable system. Some components are just inheritely flexible so we need to design for that. Like the UI, and Database. Another import issue here that some domains are very flexible themselves, think law and insurance for example. Even the business logic will change right under your nose! So in systems like these, you need to design you business rules, with a lot of flexibility in mind. It is, in systems like these, that knowing the component principles will come in handy.
The Stable Abstraction Principle
Last of the component principles in the SAP and it states the following:
A component should be as abstract as it is stable.
You might be wondering; what the heck is an abstract component. At least, I was was I first read it. How can a component be abstract? Well, Uncle Bob describes an abstract component to be a component that (only) contains Interfaces, and is thus very stable. It makes the perfect component for unstable components to depend upon. And in statically types languages like Java or C# it should be a common practice.
I remember I needed to write a new (client-side) API implementation for a framework we developed ourselves. In the old implementation, the core business logic depended heavily on services, data-transfer objects and other classes from the API. Yet, for the refactoring I wanted to switch these dependencies and so I made the API a plugin to the business logic. It was really interesting to see the web of dependencies the old implementation had compared with the new version. Since I changed all these data-transfer objects; in the old system, all these objects leaked into the core of the system. In some cases, “entity” classes we just being serialized to json and thrown over http. But to cut a long story short; I made the entry point for the API, a Service (and some data-transfer objects), an interface in the core and implemented it in the API component. The abstract part of the API that now resided in the business logic could have easily been extracted to it’s own component, but we never did.
If you are reading this and you mainly program in a dynamically typed language this might all sound really stupid to you because; in dynamically typed languages, this problem does not exist, nor do all the dependencies I discussed.
But let’s get back to the SAP. So the SAP says that components should have the correct balance of abstraction and stability. Indirectly this means that stable components should always contains some level of abstraction, and unstable components are aught to have concrete implementations. This is an interesting think to keep in mind while creating components and splitting them up.
So a stable component should contain lots of abstract classes and interfaces whereas and unstable component does not.
The combination of the SAP and the SDP describe the DIP for components. For lower level entities like abstract classes or interfaces it is easy, they are either abstract or not. But for Components it is more intricate since we allow for a fine balance between partially abstract and partially stable. With classes there is no shade of gray, it’s either abstract or not.
But how do we measure abstraction for components? Well in Clean Architecture there is a nice description for a formula. It is simply the ratio of interfaces and abstract classes to the total of classes in that component.
- Nc: The number of classes in the component.
- Na: The number of abstract classes and interfaces in the component.
- A: Abstractness. A = Na / Nc.
The metric ranges for [0,1]. A value of 0 implies that the component has no abstract classes or interfaces and a value of 1 implies it only has abstract classes and/or interfaces
So, now we have a way to describe stability and abstraction, and thus, we can define a relationship between abstractness and stability. For example if we have a component that has 0 stability and 0 abstractness it means we have a very stable, concrete component. Which we probably have to do something about. What we often want is to have values that are somewhat in the middle range that are balanced. We would not want to get closely near a value of [0,0] or [1,1] since these are what Uncle Bob describes as the “Zone of Pain” and “The Zone of Uselessness” respectively.
The Zone of Pain is a highly stable and concrete component. Such components are what we call rigid, they cannot be extended because they are concrete and very difficult to change due to the fact it’s so stable.
The Zone of Uselessness is a highly abstract component, yet is has no dependents, and so it is useless. Imagine interfaces that were created, yet never implemented. They are useless and can be deleted without anyone noticing.
Architectural Boundaries
Now that we have looked at the component level, let’s step up one more time and go to the true architectural level. On this level the impact of the DIP is still noticeable, just on a larger scale.
As I hinted earlier in this blog; the DIP on the architectural level is all about creating some sort of a plugin architecture. You may have your favorite variant (like Clean Architecture, Union, Ports and Adapters, Vertical Slice, Hexagonal) but they all describe the same thing with minor differences here and there. What is exceptionally interesting about all this is that separate people came up with a very similar idea. They noticed certain problems, and came up with similar solutions. To me, that is a sign of something very good.
So why would we want a Plugin architecture? Well because the core (business logic) is utterly unaware that the plugin even exists. With plugin architecture, we can isolate volatile components and plug them into the business logic at our own will. We can design a highly stable core, with the right amount of abstraction and create a very nice system.
But how do we create these plugins? Well, essentially they are just components, or a package of related components. Which plug in to the business logic by implementing interfaces that are defined there. This means, the core will only interact with the interfaces, and is unaware of any concrete implementations of these interfaces. This is what makes a plugin, a plugin. The core must be totally unaware that something has plugged in to it. It will simply use the concept of polymorphism to call these concrete implementations at run-time.
Uncle Bob has a rule for designing such systems which he calls the Dependency Rule and goes as follows:
Source code dependencies must point only inward, towards higher-level policies.
Nothing from core or any other layer may depend on something higher up the dependency tree. Nothing may be referenced, not classes, variables or anything else.
Impact on other paradigms
The impact of the DIP on other paradigms is pretty minimal. If we take a look at structured programming, it is simply impossible. In structured programming, there is no such thing as polymorphism. Although I bet there is some very exotic way to get some sort of an implementation of the DIP, yet I cannot find any information about it on the web. But, as with anything is Computer Science, nothing is impossible.
When we look at the functional domain the DIP makes a very small or large impact. It depends on how you look at it. I’ve talked about this in previous blogs on SOLID. In the functional domain we design systems based on abstract data(structures) and function composition. When you create something in functional languages, you often get SOLID principles “for free” since it is just de default way of writing code. The DIP in the functional domain is therefor second nature, you simply write code that is able to plugged-in to.
Conclusion
Alright, this was a massive and fun blog to write. Just as I expected before I even started writing it. The DIP has such a large impact on software that it reaches into all levels of abstraction, classes, components and entire architectural structures. That’s why I personally think the DIP is the driving force of clean software. When you understand the DIP properly, you will be able to create stable, maintainable and properly functioning software. If you do not understand it, you will run into problems sooner or later.
In this blog, I tried my best to explain the DIP and how it touches all levels of abstraction. But I have barely scratched the surface of all things involved. I encourage you to pick up a book on any of the Plugin Architecture variants. My favorite is Clean Architecture, by Uncle Bob. (You might have guessed that already.) However, the other books are nice as well.
Writing this blog made me dive deeper into the component principles which were very interesting to revisit again. I’ve read them a long time ago, and forgot about them. So refreshing my memory about these principles was very interesting. I think, after writing this blog, I wont forget about them this easily.
#end
01010010 01110101 01100010 01100101 01101110
References
[1] Clean Architecture – https://www.oreilly.com/library/view/clean-architecture-a/9780134494272/
[2] Agile Software Development: Principles, Patterns, and Practices – https://books.google.nl/books?id=0HYhAQAAIAAJ&redir_esc=y&hl=nl

Recent Comments